※当記事は、2016年に旧LifeKeeper Blogへ投稿された記事を、若干の修正のうえ再掲したものです。
こんにちは。サイオステクノロジープロダクト開発1部 宇野です。
第2回、第3回でリソース監視、リカバリーの短縮、ノード監視、リカバリーの短縮に取り組んできました。今回はこれまで紹介した以外の方法について考えてみます。
方法1. ローカルリカバリーの無効化による切り替え処理の短縮
LifeKeeperではリソース障害発生時、フェイルオーバーによるリカバリーの前に、障害の発生したノードでの復旧(ローカルリカバリー)を試みます。この処理に成功した場合、フェイルオーバーは引き起こさずに、稼働していたアクティブノードで復旧します。失敗した場合は、フェイルオーバーに処理が移ります。
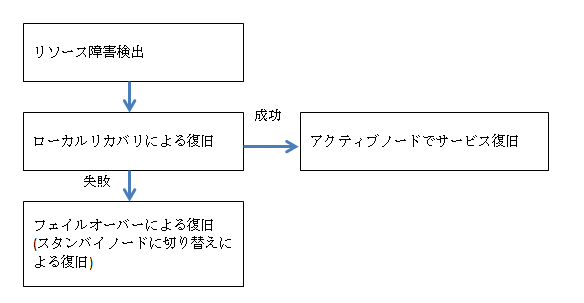
ローカルリカバリーは、成功すればフェイルオーバーが不要となりリカバリーに要する時間の短縮となりますが、失敗した場合は失敗後にフェイルオーバーをしますので、サービス停止の停止時間が長くなってしまいます。
今回はフェイルオーバーでしかリカバリー出来ない障害を手動で引き起こし、ローカルリカバリーにどの程度の時間を要したのか測定しました。またローカルリカバリーをオフにすることでどの程度リカバリーに要する時間が短縮されるのか確認してみました。
リソース障害時の処理となりますので、以下のパラメータの間隔で行われる監視処理で異常と判定される障害を引き起こします。具体的にはpostgresの実行ファイルが再起動出来なくする(実行ファイルから実行権限を取り除く)擬似障害環境を用意して、postgresプロセスを停止しました。
最初に、比較用にローカルリカバリーがオンの状態でリカバリーに要した時間を測定します。監視処理の間隔は第三回で確認した以下の最小値を使用しました。
LKCHECKINTERVAL=26
以下の様にプロセスを確認して、実行権限を取り外して、プロセスを停止しました。
1.postgresプロセスを確認
[root@pd108 ~]# ps afx | grep postgres
11621 pts/0 S+ 0:00 \_ grep --color=auto postgres
10322 ? S 0:00 /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/data -i -k /tmp -p 5432 -d 5
10324 ? Ss 0:00 \_ postgres: checkpointer process
10325 ? Ss 0:00 \_ postgres: writer process
10326 ? Ss 0:00 \_ postgres: wal writer process
10327 ? Ss 0:00 \_ postgres: autovacuum launcher process
10328 ? Ss 0:00 \_ postgres: stats collector process
2.実行権限を停止する
[root@pd108 ~]# chmod 644 /usr/local/pgsql/bin/postgres
*必ず、元の権限を確認しておきます。またテストが終わったら、元の権限に戻します。
3.プロセスを停止する。
[root@pd108 ~]# killall /usr/local/pgsql/bin/postgres
停止したプロセスを、次の監視処理が検出して、障害として切り替わりました。その際のログは以下です。
# 障害を検出した際のログです。
Aug 31 14:13:26 pd108 quickCheck[3303]: INFO:RKBase:quickCheck::001001:Calling sendevent for resource "pgsql-5432" on server "pd108.labs.sios.com"
Aug 31 14:13:26 pd108 lkexterrlog[3435]: INFO:lkexterrlog:quickCheck:pgsql-5432:010120:Extended logs saved to /var/log/lifekeeper.err.
# ローカルリカバリーを開始しました。
Aug 31 14:13:26 pd108 recover[3430]: NOTIFY:lcd.recmain:recover:pgsql-5432:011115:BEGIN recover of "pgsql-5432" (class=pgsql event=dbfail)
Aug 31 14:13:26 pd108 recover[3430]: ERROR:lcd.recover:recover:pgsql-5432:004779:resource "pgsql-5432" with id "pd108.pgsql-5432" has experienced failure event "pgsql,dbfail"
Aug 31 14:13:26 pd108 recover[3430]: INFO:lcd.recover:recover:pgsql-5432:004784:attempting recovery using resource "pgsql-5432" after failure by event "pgsql,dbfail" on resource "pgsql-5432"
Aug 31 14:13:26 pd108 dbfail[3445]: INFO:RKBase:dbfail::000000:BEGIN dbfail of "pgsql-5432" on server "pd108.labs.sios.com"
Aug 31 14:13:45 pd108 dbfail[3445]: INFO:RKBase:dbfail::001022:END failed hierarchy "dbfail" of resource "pgsql-5432" on server "pd108.labs.sios.com" with return value of 1
Aug 31 14:13:45 pd108 lkexterrlog[4780]: INFO:lkexterrlog:recover:pgsql-5432:010120:Extended logs saved to /var/log/lifekeeper.err.
Aug 31 14:13:45 pd108 recover[3430]: ERROR:lcd.recover:recover:pgsql-5432:004786:recovery failed after event "pgsql,dbfail" using recovery at resource "pgsql-5432" on failing resource "pgsql-5432"
#ローカルリカバリーに失敗しました。
Aug 31 14:13:45 pd108 recover[3430]: ERROR:lcd.recover:recover:pgsql-5432:004028:all attempts at local recovery have failed after event "pgsql,dbfail" occurred to resource "pgsql-5432"
Aug 31 14:13:45 pd108 recover[3430]: INFO:lcd.recover:recover:pgsql-5432:004790:removing resource "pgsql-5432" for transfer
# ローカルリカバリーに失敗した為、フェイルオーバー処理を開始します。
Aug 31 14:13:45 pd108 remove[4811]: INFO:RKBase:remove::000000:BEGIN remove of "pgsql-5432" on server "pd108.labs.sios.com"
<以下省略>
# 切り替え先のノードでPostgreSQLのリソースが起動完了しました。
Aug 31 14:14:24 pd109 restore[20369]: INFO:RKBase:restore::000000:BEGIN restore of "pgsql-5432" on server "pd109.labs.sios.com"
Aug 31 14:14:24 pd109 restore[20369]: INFO:pgsql:restore::113041:server starting
Aug 31 14:14:27 pd109 restore[20369]: INFO:RKBase:restore::000000:END successful restore of "pgsql-5432" on server "pd109.labs.sios.com"
ローカルリカバリーをオンにした状態では、上記のように障害を検出してからPostgreSQLリソースが起動完了するまでに61秒を要しました。
次に、ローカルリカバリーをオフにして同じテストを行ってみました。
ローカルリカバリーをオフにする場合は、lkpolicyコマンドを使用してオン/オフすることが出来ます。以下のコマンドは、ノード全体のローカルリカバリーをオフにする方法となります。リソース毎に設定する場合は、”tag=”リソース名” を使用してください。
[root@pd108 ~]# lkpolicy -s LocalRecovery –off
ローカルリカバリーをオフにして同じテストを行った場合、以下の様にログが出力しました。
# 障害を検出した際のログです。
Aug 31 15:22:46 pd108 quickCheck[14791]: INFO:RKBase:quickCheck::001001:Calling sendevent for resource "pgsql-5432" on server "pd108.labs.sios.com"
Aug 31 15:22:46 pd108 lkexterrlog[14939]: INFO:lkexterrlog:quickCheck:pgsql-5432:010120:Extended logs saved to /var/log/lifekeeper.err.
#ローカルリカバリーを開始します。
Aug 31 15:22:46 pd108 recover[14934]: NOTIFY:lcd.recmain:recover:pgsql-5432:011115:BEGIN recover of "pgsql-5432" (class=pgsql event=dbfail)
Aug 31 15:22:46 pd108 recover[14934]: ERROR:lcd.recover:recover:pgsql-5432:004779:resource "pgsql-5432" with id "pd108.pgsql-5432" has experienced failure event "pgsql,dbfail"
#ローカルリカバリーは無効化されている事を確認しました。その為、ローカルリカバリーは行われません。
Aug 31 15:22:46 pd108 recover[14934]: ERROR:lcd.recover:recover:pgsql-5432:004780:local recovery is disabled by the current settings. The recovery of resource "pgsql-5432" will not be attempted.
Aug 31 15:22:46 pd108 recover[14934]: INFO:lcd.recover:recover:pgsql-5432:004790:removing resource "pgsql-5432" for transfer
#フェイルオーバー処理を開始します。
Aug 31 15:22:46 pd108 remove[14949]: INFO:RKBase:remove::000000:BEGIN remove of "pgsql-5432" on server "pd108.labs.sios.com"
<以下省略>
# 切り替え先のノードでPostgreSQLのリソースが起動完了しました。
Aug 31 15:23:26 pd109 restore[31024]: INFO:RKBase:restore::000000:BEGIN restore of "pgsql-5432" on server "pd109.labs.sios.com"
Aug 31 15:23:27 pd109 restore[31024]: INFO:pgsql:restore::113041:server starting
Aug 31 15:23:29 pd109 restore[31024]: INFO:RKBase:restore::000000:END successful restore of "pgsql-5432" on server "pd109.labs.sios.com"
ローカルリカバリーをオフにした状態では、障害を検出してからPostgreSQLリソースが起動完了するまでに43秒を要しました。
今回の環境ではローカルリカバリーのオン、オフで61秒、43秒と18秒程度の差が確認できました。ローカルリカバリーはフェイルオーバーを起こさずに障害を復旧する可能性のある処理ですが、復旧しない場合もあります。その為、上記のように事前にローカルリカバリーをオフにして運用する事も可能です。
方法2.PostgreSQL ARKのパラメータ
PostgreSQL ARKは以下の様に多数のパラメータを用意していますが、初期設定が全て最短の処理となるよう設計されていました。その為、インストール後のパラメータのカスタマイズによる障害検出時間の短縮やリカバリー処理を早める事は出来そうにありませんでした。その為、デフォルトの設定で問題なく稼働するようであれば、パラメータ変更を行なわずに利用して頂くのが最も停止時間を短縮する方法でした。
以下がPostgreSQL ARKのパラメータ一覧です。
|
パラメータ名 |
パラメータの意味 |
設定値 |
デフォルト値 |
適応タイミング |
備考 |
|
LKPGSQL_KILLPID_TIME |
プロセス ID が停止した後、そのプロセスに対する再チェックを行うまでの時間を秒単位で指定します。 |
整数値 |
3 |
適宜 |
デフォルト値より小さい場合は、デフォルト値が設定されます。 |
|
LKPGSQL_CONN_RETRIES |
旧 LKPGSQLMAXCOUNT - 操作 (開始もしくは停止) を行った後、クライアント接続を試みる回数を指定します。 |
整数値 |
12 |
適宜 |
デフォルト値より小さい場合は、デフォルト値が設定されます。 |
|
LKPGSQL_ACTION_RETRIES |
アクションコマンドに失敗するまで、開始と停止を試行する回数を指定します。 |
整数値 |
4 |
適宜 |
デフォルト値より小さい場合は、デフォルト値が設定されます。 |
|
LKPGSQL_STATUS_TIME |
status コマンドのタイムアウト時間を秒単位で指定します。 |
整数値 |
17 + (3 * LKPGSQL_KILLPID_TIME) |
適宜 |
デフォルト値より小さい場合は、デフォルト値が設定されます。 |
|
LKPGSQL_QCKHANG_MAX |
データベースインスタンスがフェイルオーバー / sendevent を発生させるまでに許容される、quickCheckがハングする回数を指定します。 |
整数値 |
2 |
リソース作成時 |
1より小さい場合は、デフォルト値が設定されます。 |
| LKPGSQL_CUSTOM_DAEMON | postgres デーモン(postgres.bin,postmaster,postgres,edb-postgres) に対する追加の別名の指定を許可します。 | 文字列 | (未設定) | リソース作成時 | |
| LKPGSQL_IDIRS | パラメータの値に設定したdatadir のエントリを含むインスタンスをimmediate オプションを使用してシャットダウンします。 | 文字列 | (未設定) | 適宜 | |
| LKPGSQL_SDIRS | パラメータの値に設定したdatadir のエントリを含むインスタンスをsmart オプションを使用してシャットダウンします。 | 文字列 | (未設定) | 適宜 | |
| LKPGSQL_DISCONNECT_CLIENT | データベースに障害が発生している間の PostgreSQL リソース階層の振る舞いを制御します。本パラメータを有効にすると、クライアントプロセスに SIGTERM シグナルが送信され、データベースから強制的に切断されます。この処置は、postmasterプロセスがローカルリカバリー中に稼働していない場合のみに取ることができます。 |
0: 無効 1: 有効 |
1 | 適宜 | PostgreSQL 8.2以降では、本パラメータをご利用いただけません。 |
| LKPGSQL_DISCONNECT_CLIENT_BYTAG | LKPGSQL_DISCONNECT_CLIENT と類似していますが、この設定は、処置をこの設定項目で指定したカンマで区切られたタグのリストに限定します。 | 文字列 | (未設定) | 適宜 | PostgreSQL 8.2以降では、本パラメータをご利用いただけません。 |
| LKPGSQL_RESUME_PROC | プロセスの停止状態の検出時 (プロセス状態が T )、再開するか無視するかを決定します。 |
0: 無視 1: 再開 |
1 | 適宜 | |
| LKPGSQLDEBUG |
PostgreSQL database kit および postgres データベースのデバッグを有効にします。0 ~ 5 の値が有効です。 この設定項目は、オプション -d <LKPGSQLDEBUG> を使用して postmaster データベースへと渡されます。 |
0~5の整数値 | 0 | 適宜 | 設定可能な値でない場合は、デフォルト値が設定されます。 |
※参考:SIOS Protection Suite for Linux v9.3 PostgreSQLパラメーター一覧
以上が、4回にわたって紹介したHigher Availability(より高い可用性)を実現する手法です。
まとめ
これまでの検証で、アプリケーション監視時間間隔(LKCHKINTERVAL)の短縮(120秒→30秒)、ノード障害検出時間(LCMHBEATTIME×LCMNUMHBEATS)の短縮(15秒→4秒)、フェイルオーバー時間の短縮(ローカルリカバリーON/OFF)などの調整(43秒→18秒)というPostgreSQL ARKにおけるLifeKeeperチューニングのベストプラクティスが得られました。
アプリケーション障害の場合、30秒以内にPostgreSQLの障害を検知し、11秒~18秒でフェイルオーバーが完了します。適切なシステムリソース(CPU、メモリー)を配置することで障害検知から待機系でのサービス再開まで60秒以内で完了させることが可能です。
障害検知にかかる時間の短縮
ノード監視 15秒→4秒
リソース監視 120秒→30秒
アプリケーション起動時間の短縮
ローカルリカバリー時のアプリの起動 ローカルリカバリーON→OFF
フェイルオーバー時のアプリの起動 11秒~18秒(DBのリカバリー処理が無い場合)
DBのリカバリー処置に要する時間 障害時の書き込み系トランザクションに依存