※当記事は、2016年に旧LifeKeeper Blogへ投稿された記事を、若干の修正のうえ再掲したものです。
こんにちは。サイオステクノロジープロダクト開発1部 宇野です。
第一回では、デバッグオプションを使用したリソース監視処理時間の測定方法を紹介しました。今回はデバッグオプションを有効にして監視処理時間の測定を行ってみます。
LifeKeeper が行う各リソースの状況を確認する監視処理は、初期設定として監視パラメータ(LKCHECKINTERVAL)で設定された値(120)秒の間隔で行われます。LifeKeeper を起動した時間を起点にして、以下の様に120秒間隔で各リソースの監視処理(quickCheck)スクリプトが直列に実行されます。
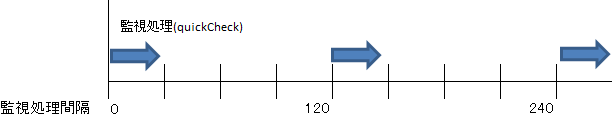
この監視処理が完了するまでに要する時間は、負荷状況やハードウェアリソース、外的要因等の影響で変わってきます。次回の監視処理までに完了しなければいけないので、十分な間隔を設けて処理が行われるよう設定して頂く事が推奨されています。その為、120秒より短くすることはサポートの観点では推奨していません。誤検知した場合に、値を120秒に戻していただく事になります。
ただし今回は、より障害の検出速度を高める事に対する検証となりますので、現在のリソース構成ではどの程度監視処理に時間を要しているかを測定し、以下の様に監視間隔を縮小にチャレンジしてみます。
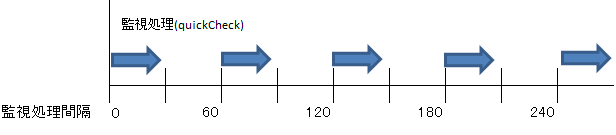
監視間隔を定義するパラメータ(LKCHECKINTERVAL)は、設定ファイル/etc/default/LifeKeeperに以下の様に定義されています。
LKCHECKINTERVAL=120
パラメータの値を変更した場合、lkcheck デーモンに変更した事を反映させる為、以下の様にLifeKeeperの再起動を行います。
# lkstop –f; lkstart
今回の検証環境は以下です。CPUコア数とメモリを多めに設定しました。
|
Server : VM(vSphere6) x2 CPU: Intel(R) Xeon(R) CPU E5-2660 0 @ 2.20GHz (4 core) MemTotal: 8073684 kB Disk /dev/sda: 17.2 GB /dev/sdb: 10.7 GB Network: 1000Mbps x2 OS : CentOS Linux release 7.2.1511 Kernel Version: 3.10.0-327.el7.x86_64 DB:postgresql v9.4.8 |
上記の構成のサーバーに、Protection Suite for Linux v9.1をインストールし、以下の様なリソース構成としました。2ノードクラスター+Quorum/Witness サーバーの構成です。
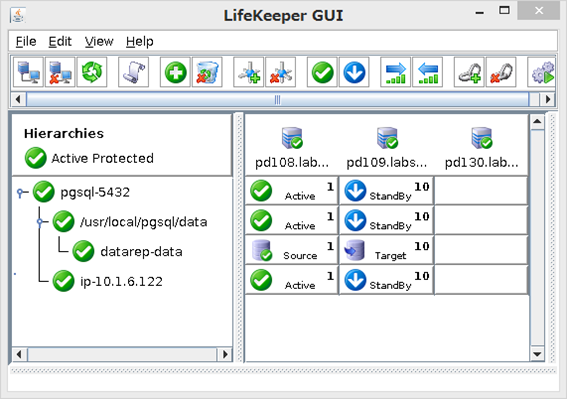
この構成で実際に行われる監視処理スクリプトで要する時間を測定します。監視処理はリソース毎に下位リソースから順に監視処理が実行されますので、Data Replicationリソース、(IP,リソース Filesystemリソース)、PostgreSQLリソースの順番でチェックされます。
監視処理が稼働している事を確認するため、Activeノード”pd108”で以下の様にデバッグオプションを有効化しました。監視処理に成功した場合、正常に稼働している事を示すログは出力しません。その為、デバッグログを有効にすることで、正常時に監視処理が終了した時のログを確認することが出来るようになります。
[root@pd108 ~]# flg_list
debug_ip
debug_filesys
debug_dr
[root@pd108 ~]# grep LKPGSQLDEBUG /etc/default/LifeKeeper
LKPGSQLDEBUG=5
初期設定の120秒での監視間隔で監視処理に要する時間を測定します。
まずはアイドル時(postgresqlにアクセスが無い状態)の/var/log/lifekeeper.logを確認して監視処理で出力するログを確認して時間を測定しました。アイドル時の監視処理に要した時間は、以下にログを抜粋して張り付けました。監視処理には15秒を要しました。
--- アイドル時 ---
Aug 19 10:56:43 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000:/opt/LifeKeeper/lkadm/subsys/scsi/netraid/bin/mdadm
Aug 19 10:56:43 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000:mdadm - v3.2.6 - 25th October 2012
Aug 19 10:56:43 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000:/opt/LifeKeeper/lkadm/subsys/scsi/netraid/bin/mdadm
Aug 19 10:56:43 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000:mdadm - v3.2.6 - 25th October 2012
Aug 19 10:56:43 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000:getId: -b: -p:1 -i: -s:pd108.labs.sios.com /dev/sdb1
Aug 19 10:56:43 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000:getId: /opt/LifeKeeper/lkadm/subsys/scsi/DEVNAME/bin/getId -b "/dev/sdb1" returned "/dev/sdb1"
Aug 19 10:56:43 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000:get mirrorinfo 0: pd108.labs.sios.com#0010#001type:1#0010#0010#0010#001#0010#0010#0010#001#0011
Aug 19 10:56:43 pd108 quickCheck[10972]: DEBUG:dr:::104001:get mirrorinfo 0: pd108.labs.sios.com#0010#001type:1#0010#0010#0010#001#0010#0010#0010#001#0011
Aug 19 10:56:43 pd108 quickCheck[10972]: DEBUG:dr:::104001:get mirrorinfo 0: pd109.labs.sios.com#0011#001172.16.1.109#0010#0010#0010#001#0010#0010#0010#001#0011
:
<省略>
:
Aug 19 10:56:58 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000: DEBUG(pgsql): DESTROY: Destroying object defined for resource (pgsql-5432)
Aug 19 10:56:58 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000: DEBUG(pgsql): cleaner: starting for 5432, /usr/local/pgsql/data, /tmp, psql, pg_ctl, postgres on pd108.labs.sios.com (11071)
Aug 19 10:56:58 pd108 quickCheck[11071]: INFO:RKBase:quickCheck::000000:#011DEBUG(pgsql):#011cleaner: [our pid=11071] clients=<>
Aug 19 10:56:58 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000: DEBUG(pgsql): cleaner: [our pid=11071] clients=<>
Aug 19 10:56:58 pd108 quickCheck[11071]: INFO:RKBase:quickCheck::000000:#011DEBUG(pgsql):#011cleaner: [our pid=11071] utils=<>
Aug 19 10:56:58 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000: DEBUG(pgsql): cleaner: [our pid=11071] utils=<>
Aug 19 10:56:58 pd108 quickCheck[11071]: INFO:RKBase:quickCheck::000000:#011DEBUG(pgsql):#011cleaner: [our pid=11071] No pid(s) where found to clean up on behalf of 11071
Aug 19 10:56:58 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000: DEBUG(pgsql): cleaner: [our pid=11071] No pid(s) where found to clean up on behalf of 11071
Aug 19 10:56:58 pd108 quickCheck[11071]: INFO:RKBase:quickCheck::000000:#011DEBUG(pgsql):#011cleaner: [our pid=11071] Set to return 0 (signaled )
Aug 19 10:56:58 pd108 lkcheck[1928]: ERROR:runit:uncaught_error::000000: DEBUG(pgsql): cleaner: [our pid=11071] Set to return 0 (signaled )
次に運用時(TPCC-UVa を使用したRun testを通常運用時に見立てて実施)に監視処理に要した時間を測定しました。TPCC-UVaはTPC-Cに準じたベンチマークソフトウェアであり実際の物流業務におけるトランザクション処理に近い環境を作りだすとの事と、2014年に久しぶりに新しいバージョンが公開されていた為、運用時の負荷を実現するベンチマークとして今回使用して見ました。Run test実施時には、CPUの使用率が50%前後まで上がりましたが、4Coreで使用している事もあり、以下のログからも確認できるように、実際に監視処理に要した時間は15秒でした。アイドル時と比較しても差は出ませんでした。
--- Run test時---
Aug 18 11:22:01 pd108 lkcheck[11494]: ERROR:runit:uncaught_error::000000:/opt/LifeKeeper/lkadm/subsys/scsi/netraid/bin/mdadm
Aug 18 11:22:01 pd108 lkcheck[11494]: ERROR:runit:uncaught_error::000000:mdadm - v3.2.6 - 25th October 2012
Aug 18 11:22:01 pd108 lkcheck[11494]: ERROR:runit:uncaught_error::000000:/opt/LifeKeeper/lkadm/subsys/scsi/netraid/bin/mdadm
Aug 18 11:22:01 pd108 lkcheck[11494]: ERROR:runit:uncaught_error::000000:mdadm - v3.2.6 - 25th October 2012
Aug 18 11:22:01 pd108 lkcheck[11494]: ERROR:runit:uncaught_error::000000:getId: -b: -p:1 -i: -s:pd108.labs.sios.com /dev/sdb1
Aug 18 11:22:01 pd108 lkcheck[11494]: ERROR:runit:uncaught_error::000000:getId: /opt/LifeKeeper/lkadm/subsys/scsi/DEVNAME/bin/getId -b "/dev/sdb1" returned "/dev/sdb1"
Aug 18 11:22:01 pd108 lkcheck[11494]: ERROR:runit:uncaught_error::000000:get mirrorinfo 0: pd108.labs.sios.com#0010#001type:1#0010#0010#0010#001#0010#0010#0010#001#0011
Aug 18 11:22:01 pd108 quickCheck[24481]: DEBUG:dr:::104001:get mirrorinfo 0: pd108.labs.sios.com#0010#001type:1#0010#0010#0010#001#0010#0010#0010#001#0011
:
<省略>
:
Aug 18 11:22:16 pd108 lkcheck[11494]: ERROR:runit:uncaught_error::000000: DEBUG(pgsql): cleaner: starting for 5432, /usr/local/pgsql/data, /tmp, psql, pg_ctl, postgres on pd108.labs.sios.com (24585)
Aug 18 11:22:16 pd108 quickCheck[24585]: INFO:RKBase:quickCheck::000000:#011DEBUG(pgsql):#011cleaner: [our pid=24585] clients=<>
Aug 18 11:22:16 pd108 lkcheck[11494]: ERROR:runit:uncaught_error::000000: DEBUG(pgsql): cleaner: [our pid=24585] clients=<>
Aug 18 11:22:16 pd108 quickCheck[24585]: INFO:RKBase:quickCheck::000000:#011DEBUG(pgsql):#011cleaner: [our pid=24585] utils=<>
Aug 18 11:22:16 pd108 lkcheck[11494]: ERROR:runit:uncaught_error::000000: DEBUG(pgsql): cleaner: [our pid=24585] utils=<>
Aug 18 11:22:16 pd108 quickCheck[24585]: INFO:RKBase:quickCheck::000000:#011DEBUG(pgsql):#011cleaner: [our pid=24585] No pid(s) where found to clean up on behalf of 24585
Aug 18 11:22:16 pd108 lkcheck[11494]: ERROR:runit:uncaught_error::000000: DEBUG(pgsql): cleaner: [our pid=24585] No pid(s) where found to clean up on behalf of 24585
Aug 18 11:22:16 pd108 quickCheck[24585]: INFO:RKBase:quickCheck::000000:#011DEBUG(pgsql):#011cleaner: [our pid=24585] Set to return 0 (signaled )
Aug 18 11:22:16 pd108 lkcheck[11494]: ERROR:runit:uncaught_error::000000: DEBUG(pgsql): cleaner: [our pid=24585] Set to return 0 (signaled )
上記の試験を行う前に、CPU:1Core メモリ2GBの構成でアイドル時と運用時それぞれ同じ確認を行いました。この構成ではアイドル時15秒とRun test時24秒と監視処理に要する時間に差があったのですが、より現実的なハードウェアリソースでの検証を行なおうと考え、パフォーマンスを向上させました。結果として、アイドル時も運用時も監視処理にも要する時間の差は無くなりました。メモリの使用量には大きな変化が無かったので、マルチコアCPUのパフォーマンスが影響して、差が無くなったように考えられます。
ふたつのテストで確認した監視処理時間(約15秒)を元に監視間隔(LKCHECKINTERVAL)の短縮を行います。まず以下の様に実際の監視間隔より監視処理が長くなった場合に出力するメッセージを確認します。
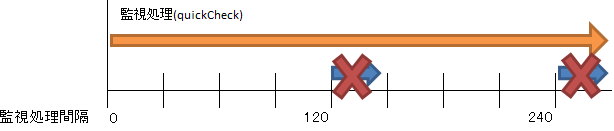
アイドル時の監視処理時間が15秒でしたので、監視間隔の設定パラメータ(LKCHECKINTERVAL)を13に変更してみました。この設定を行った場合、ほぼ確実に以下のログが13秒間隔で出力するようになりました。
ERROR:lkcheck:::006014:LKCHECKINTERVAL parameter is too short. It is currently set to 13 seconds. It should be at least 16 seconds. Please adjust this parameter in /etc/default/LifeKeeper and execute 'kill 31681' to restart the lkcheck daemon.
上記のメッセージは、監視間隔の設定パラメータ(LKCHECKINTERVAL)が短すぎる事を示しています。この場合は、監視間隔毎に実行される監視処理は実行されず、終了しなかった監視処理が終了するまで継続されます。こうなると監視処理が指定の時間内に全て完了しなくなり、障害の検出に遅延が発生する恐れがあります。その為、監視間隔が終了するために十分な値に監視間隔の設定パラメータを設定変更する必要があります。
またPostgreSQL ARK には、初期値としてLKCHECKINTERVALを26秒以下に設定した場合、以下のメッセージを出力する仕様がありました。
INFO:pgsql:quickCheck::113039:The value of the LKCHECKINTERVAL 13 is lower than the required check interval of 26 for PostgreSQL. Increase the value of LKCHECKINTERVAL.
その為、監視間隔の設定は26秒以上に設定する必要がありました。
以上の様に監視に要する時間を測定した結果と、PostgreSQL ARKの仕様を考慮し、LKCHECKINTERVAL を26秒に設定した状態でベンチマークを24時間実行しながら監視処理の時間を測定しました。
結論としては、24時間内に稼働した監視処理はすべて26秒以内に完了していました。その為、十分なハードウェアリソースを要したシステムであれば、監視処理に要する時間に差が出る事は無いという結果となりました。
もし監視処理に時間を要するケースが発生した場合は、運用で想定していた以上の負荷、もしくは物理的な障害やソフトウェアバグなどが影響している可能性があります。
以上で、リソース監視に要する時間の測定と、測定した値を元に行った監視間隔の変更の結果となります。
次回は、ノード監視の間隔を短縮した場合の挙動についてレポートします。