※当記事は、2016年に旧LifeKeeper Blogへ投稿された記事を、若干の修正のうえ再掲したものです。
こんにちは。サイオステクノロジープロダクト開発1部 宇野です。
前回は、各リソースの状態をチェックするリソース監視処理に要する時間を測定して、可能な範囲での監視間隔の短縮にチャレンジしてみました。今回は、ノード監視に要する時間を短縮する事にチャレンジしたいと思います。
今回使用した環境は、前回までのリソース監視処理の短縮でも使用した以下の環境です。
|
Server : VM(vSphere6) x2 CPU: Intel(R) Xeon(R) CPU E5-2660 0 @ 2.20GHz (4 core) MemTotal: 8073684 kB Disk /dev/sda: 17.2 GB /dev/sdb: 10.7 GB Network: 1000Mbps x2 OS : CentOS Linux release 7.2.1511 Kernel Version: 3.10.0-327.el7.x86_64 DB:PostgreSQL v9.4.8 |
上記の構成のサーバーにProtection Suite for Linux v9.1をインストールし、以下の様なリソース構成としました。2ノードクラスター+Quorum/Witness サーバーの構成です。
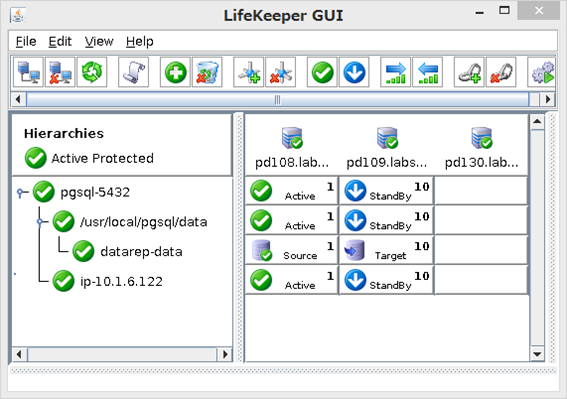
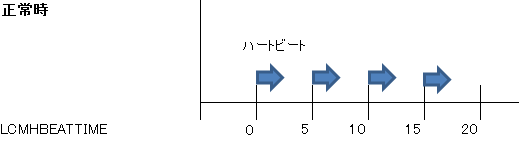
ノード監視処理は、コミュニケーションパスを経由して送信するハートビートによって行われます。初期設定では以下の値が使用されますので、正常時は5秒間隔でハートビートを送信し、死活監視を行います。
LCMHBEATTIME,=5 # ハートビートの送信間隔 (秒)
LCMNUMHBEATS=3 # ハートビート切断と判定するまでの試行回数
コミュニケーションパスが切断された場合は5秒をリミットとしてハートビートを送信し、3回失敗するとコミュニケーションパス障害となります。その為、コミュニケーションパスの障害検出まで約15秒かかります。
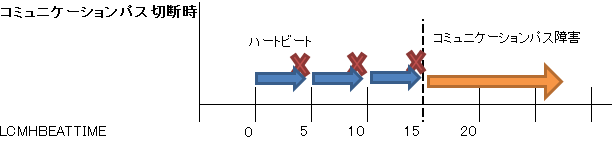
全てのコミュニケーションパスが障害として判定された場合、ノード障害と判定されノードフェイルオーバーが発生します。
ハートビートの送信間隔、試行回数を指定するパラメータの値を短くすることで、障害検出までの時間を短縮できます。その為、これら2つのパラメータの短縮ににチャレンジしたいと思います。
■準備
パラメータを変更する前に、短縮した事が原因で発生するコミュニケーションパスの障害誤検知が、最終的にノード障害フェイルオーバーへとつながらないよう、事前にノード障害フェイルオーバーを停止します。こうする事で短縮時間の測定テストで不要なノード障害フェイルオーバーの発生を抑止します。
ノード障害フェイルオーバーを無効化するためには、LifeKeeper GUI のノードで右クリックをして、Properties を選択します。以下のProperties Panel画面を開きますので、”Set Confirm Failover On”で該当するサーバーに全てチェックを入れてください。この項目にチェックする事でノード障害フェイルオーバーが発生しなくなります。この処理は念のため全てのノードを対象に行います。
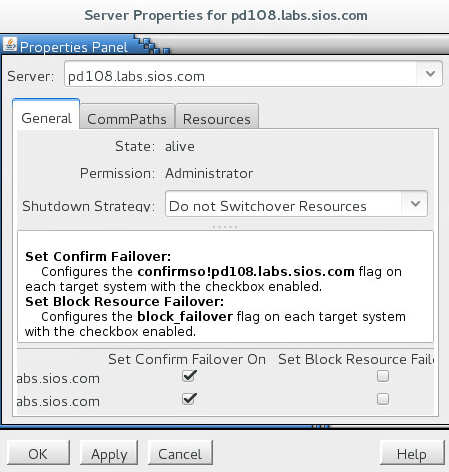
■パラメータの調整
ノード障害フェイルオーバーを停止した後、パラメータの値を調整して、コミュニケーションパスに流れるハートビートが途切れないかどうかログを監視します。最初に全ノードに対して、各パラメータの最小値を設定しました。最小値は以下となります。
LCMHBEATTIME=1 #ハートビートの送信間隔 (秒)
LCMNUMHBEATS=2 #ハートビート切断と判定するまでの試行回数
パラメータの設定変更後は、LifeKeeperを再起動する必要があります。
# lkstop –f ; lkstart
最小値に変更した場合、ネットワークは正常にもかかわらず以下のメッセージを出力し、ハートビート喪失を検出しました。
Aug 25 14:14:31 pd109 lcm[3281]: INFO:lcm.tli_hand:::005257:missed heartbeat 1 of 2 on dev 10.1.6.109/10.1.6.108 (lcm driver number = 1256).
設定後に上記のメッセージが出力する場合は、ノード間のコミュニケーションパスでのハートビートが正常に届いていない事を示しています。その為、この監視間隔、試行回数では正常に監視が行えませんので、パラメータの値を以下の値まで増やしました。
LCMHBEATTIME=2 #ハートビートの送信間隔 (秒)
LCMNUMHBEATS=2 #ハートビート切断と判定するまでの試行回数
パラメータの設定変更後は、LifeKeeperを再起動する必要があります。
# lkstop –f ; lkstart
第2回のブログで使用したTPCC-UVa のRun testを実行して、通常の運用時の状態を24時間再現しました。その為、上記の値であっても、通常の運用には耐えられる事を確認しました。
■フェイルオーバーテスト
最小値が分かりましたので、デフォルト値と最小値でノード障害テストを行い、フェイルオーバーが完了するまでの時間を確認しました。
先にデフォルト値でフェイルオーバーに要する時間を測定しました。誤検知によるフェイルオーバーを防ぐために行った、ノード障害フェイルオーバーの停止を解除してからテストを行いました。
デフォルト値:
LCMHBEATTIME=5 # ハートビートの送信間隔 (秒)
LCMNUMHBEATS=3 # ハートビート切断と判定するまでの試行回数
1.両ノードの時間が一致している事を確認しました。
[root@pd108 ~]# ssh pd109 "hostname;date"; hostname;date
root@pd109's password:
pd109.labs.sios.com
2016年 8月 25日 木曜日 17:24:11 JST
pd108.labs.sios.com
2016年 8月 25日 木曜日 17:24:11 JST
2.pd108がアクティブ、pd109 がスタンバイノードと状態で、pd108で以下のコマンドを実行してカーネルパニックを起こしました。
# date ; sleep 1 ; echo c > /proc/sysrq-trigger
2016年 8月 25日 木曜日 17:25:43 JST
*上記の時間の1秒後にカーネルパニックを引き起こしています。
3.pd109でコミュニケーションパス障害を検出した時間は以下でした。
Aug 25 17:26:02 pd109 eventslcm[15651]: WARN:lcd.net:::004258:Communication to pd108.labs.sios.com by 172.16.1.109/172.16.1.108 FAILED
Aug 25 17:26:02 pd109 eventslcm[15654]: WARN:lcd.net:::004258:Communication to pd108.labs.sios.com by 10.1.6.109/10.1.6.108 FAILED
Aug 25 17:26:02 pd109 eventslcm[15654]: WARN:lcd.net:::004261:COMMUNICATIONS failover from system "pd108.labs.sios.com" will be started.
Aug 25 17:26:02 pd109 lifekeeper[15710]: NOTIFY:event.comm_down:::010466:COMMUNICATIONS pd108.labs.sios.com FAILED
4.pd109でフェイルオーバーが完了したのは以下の時間でした。
Aug 25 17:26:13 pd109 lcdmachfail[15806]: NOTIFY:lcd.lcdmf:::011065:FAILOVER RECOVERY OF MACHINE pd108.labs.sios.com FINISHED
以上より、デフォルト値での障害検出には、18秒かかり、ノードフェイルオーバーが完了するまでには29秒の時間が必要であることがわかりました。
続いて、設定可能な最小値でフェイルオーバーテストを実施します。
最小値:
LCMHBEATTIME=2 # ハートビートの送信間隔 (秒)
LCMNUMHBEATS=2 # ハートビート切断と判定するまでの試行回数
1.両ノードの時間が一致している事を確認します。
[root@pd108 ~]# ssh pd109 "hostname;date"; hostname;date
root@pd109's password:
pd109.labs.sios.com
2016年 8月 25日 木曜日 18:03:42 JST
pd108.labs.sios.com
2016年 8月 25日 木曜日 18:03:42 JST
2.pd108がアクティブ、pd109 がスタンバイノードと状態で、pd108で以下のコマンドを実行してカーネルパニックを起こします。
[root@pd108 ~]# date ; sleep 1 ; echo c > /proc/sysrq-trigger
2016年 8月 25日 木曜日 18:04:21 JST
*上記の時間の1秒後にカーネルパニックを引き起こしています。
3.pd109でコミュニケーションパス障害を検出した時間は以下でした。
Aug 25 18:04:27 pd109 eventslcm[22480]: WARN:lcd.net:::004258:Communication to pd108.labs.sios.com by 10.1.6.109/10.1.6.108 FAILED
Aug 25 18:04:27 pd109 eventslcm[22483]: WARN:lcd.net:::004258:Communication to pd108.labs.sios.com by 172.16.1.109/172.16.1.108 FAILED
Aug 25 18:04:27 pd109 eventslcm[22483]: WARN:lcd.net:::004261:COMMUNICATIONS failover from system "pd108.labs.sios.com" will be started.
Aug 25 18:04:27 pd109 lifekeeper[22538]: NOTIFY:event.comm_down:::010466:COMMUNICATIONS pd108.labs.sios.com FAILED
4.pd109でフェイルオーバーが完了したのは以下の時間でした。
Aug 25 18:04:38 pd109 lcdmachfail[22602]: NOTIFY:lcd.lcdmf:::011065:FAILOVER RECOVERY OF MACHINE pd108.labs.sios.com FINISHED
以上より、最小値での障害検出には、5秒かかり、ノードフェイルオーバーが完了するまでには16秒の時間が必要であることがわかりました。
今回の検証では、ハートビート間隔および試行回数を可能な最小の値を設定する事で、障害の復旧が13秒早くなりました。
注意事項としては、今回の検証環境は上記の設定ではハートビートの応答が4秒止まるだけでコミュニケーションパスの障害を検出します。その為、ノード障害やネットワーク障害が発生しなくても4秒以上応答が止まるようなシステム状況が発生した場合、LifeKeeperはコミュニケーションパス障害を検出します。この事で障害の誤検知となる場合もあります。
次回は、可用性を高めるその他の施策について確認します。