※当記事は、2016年に旧LifeKeeper Blogへ投稿された記事を、若干の修正のうえ再掲したものです。
こんにちは。サイオステクノロジープロダクト開発1部 宇野です。今回から“Higher Availability DB”について、計4回にわたって紹介いたします。
HAクラスターとは、高可用性(High Availability)を実現するクラスターシステムの事ですが、Higher Availabilityは、従来のHAクラスターで提供するHAよりさらに高い可用性を実現する事を指しています。今回はDBと限定しており、その中でもPostgreSQLを対象としたHAより高い可用性を目指す手法を試みます。
高い可用性を考える為に、まずは従来のHAクラスターでのリカバリについて考えます。HAクラスターソフトウェアである LifeKeeper では、以下1~4の順序でリカバリー処理が行われます。
- 一定間隔で行われる監視処理
- 監視による障害検出
- ローカルリカバリー(障害ノードでのサービス再起動によるリカバリ)
- フェイルオーバーリカバリー(ノードを変更してサービスを起動する復旧)
HAより高い可用性を目指す場合、これらの処理を迅速に行う、もしくはリカバリーの望めない処理をスキップする等の方法を取る事で、より早いリカバリーを目指すことが可能です。
これらの処理を迅速にと紹介しましたが、具体的には以下の二つを短縮します。
2. 監視による障害検出
4. フェイルオーバーリカバリー(ノードを変更してサービスを起動する復旧)
まず、監視間隔を短くすることによる、障害検出までの時間短縮を実現してみます。
LifeKeeper for Linux の監視処理は、デフォルトの120秒 (LKCHECKINTERVAL=120) 間隔で行うよう設定されています。この間隔を短縮する事で、より早く障害を検出できます。ただし短縮する場合は以下の点に気を付けて頂く必要があります。
- LifeKeeper for Linuxは LKCHECKINTERVAL の間隔内で全てのリソースの監視処理を終える必要があります。その為、監視処理の間隔が短縮しすぎて、リソースの数やリソースの種類を考慮して監視間隔を設定する必要があります。
- システム平常時とシステム高負荷時では監視処理に時間が変わる場合があります。
上記の事から、通常サイオスから監視感覚をデフォルト値より短縮することを推奨するご案内はしておりませんが、今回の場合はリソース数が少なく、かつ高負荷状態にならないシステムという想定のもと、設定値を短くすることで障害検出までの時間短縮を行えました。
なお各リソースの監視処理については通常ログ(/var/log/lifekeeper.log)に出力する事はありません。具体的に各リソースの監視処理にどのような処理を行い、その程度時間を要しているのか確認する為、各リソースのデバッグモードを有効にして頂くことで確認可能です。
例として、以下の様な構成であった場合、PostgreSQL, File system, Data Replication,IPリソースの監視処理をデバッグモードで確認する事で監視間隔を検討する情報が取得できます。
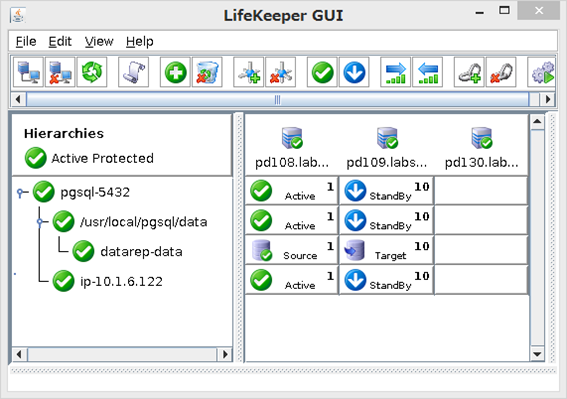
- PostgreSQL リソースの場合は、以下のパラメータを/etc/default/LifeKeeperに追加し、LifeKeeperを再起動する事で監視処理に要する時間を測定しました。
LKPGSQLDEBUG=5
PostgreSQL リソースのデバッグモードを無効化する場合は、パラメータを削除して、LifeKeeperを再起動が必要です。
- File System, Data Replication, IPリソースを監視するために、それぞれ以下のコマンドでデバッグフラグを作成し、出力するログから処理時間を測定します。
# flg_create –f debug_filesys
# flg_create –f debug_dr
# flg_create –f debug_ip
フラグ設定の状況については、以下のコマンドで確認可能です。
# flg_list
デバッグモードを無効にする場合は、以下のコマンドでフラグを削除します。
# flg_remove –f debug_filesys
# flg_remove –f debug_dr
# flg_remove –f debug_ip
デバッグモードは、調査を行う場合に詳細ログを出力して使用しますが、普段の運用では、ログの出力が冗長となり運用には向きません。その為、調査が終わりましたらデバッグモードは無効化してください。
次回は、実際の測定ログを確認してゆきたいと考えています。